NPTEL Python for Data Science Assignment 4 Answers 2023:- All the Answers provided below to help the students as a reference, You must submit your assignment at your own knowledge.
NPTEL Python For Data Science Week 4 Assignment Answer 2023
1. Which of the following are regression problems? Assume that appropriate data is given.
- Predicting the house price.
- Predicting whether it will rain or not on a given day.
- Predicting the maximum temperature on a given day.
- Predicting the sales of the ice-creams.
Answer :- For Answer Click Here
2. Which of the followings are binary classification problems?
- Predicting whether a patient is diagnosed with cancer or not.
- Predicting whether a team will win a tournament or not.
- Predicting the price of a second-hand car.
- Classify web text into one of the following categories: Sports, Entertainment, or Technology.
Answer :- For Answer Click Here
3. If a linear regression model achieves zero training error, can we say that all the data points lie on a hyperplane in the (d+1)-dimensional space? Here, d is the number of features.
- Yes
- No
Answer :- For Answer Click Here
Read the information given below and answer the questions from 4 to 6:
Data Description:
An automotive service chain is launching its new grand service station this weekend. They offer to service a wide variety of cars. The current capacity of the station is to check 315 cars thoroughly per day. As an inaugural offer, they claim to freely check all cars that arrive on their launch day, and report whether they need servicing or not!
Unexpectedly, they get 450 cars. The servicemen will not work longer than the working hours, but the data analysts have to!
Can you save the day for the new service station?
How can a data scientist save the day for them?
He has been given a data set, ‘ServiceTrain.csv’ that contains some attributes of the car that can be easily measured and a conclusion that if a service is needed or not.
Now for the cars they cannot check in detail, they measure those attributes and store them in ‘ServiceTest.csv’
Problem Statement:
Use machine learning techniques to identify whether the cars require service or not
Read the given datasets ‘ServiceTrain.csv’ and ‘ServiceTest.csv’ as train data and test data respectively and import all the required packages for analysis.
4. Which of the following machine learning techniques would NOT be appropriate to solve the problem given in the problem statement?
- kNN
- Random Forest
- Logistic Regression
- Linear regression
Answer :- For Answer Click Here
5. After applying logistic regression, what is/are the correct observations from the resultant confusion matrix?
- True Positive = 29, True Negative = 94
- True Positive = 94, True Negative = 29
- False Positive = 5, True Negative = 94
- None of the above
Answer :- For Answer Click Here
Prepare the data by following the steps given below, and answer questions 6 and 7.
- Encode categorical variable, Service – Yes as 1 and No as 0 for both the train and test datasets.
- Split the set of independent features and the dependent feature on both the train and test datasets.
- Set random_state for the instance of the logistic regression class as 0.
6. The logistic regression model built between the input and output variables is checked for its prediction accuracy of the test data. What is the accuracy range (in %) of the predictions made over test data?
- 60 – 79
- 90 – 95
- 30 – 59
- 80 – 89
Answer :- For Answer Click Here
7. How are categorical variables preprocessed before model building?
- Standardization
- Dummy variables
- Correlation
- None of the above
Answer :- For Answer Click Here
The Global Happiness Index report contains the Happiness Score data with multiple features (namely the Economy, Family, Health, and Freedom) that could affect the target variable value.
Prepare the data by following the steps given below, and answer question 8
- Split the set of independent features and the dependent feature on the given dataset
- Create training and testing data from the set of independent features and dependent feature by splitting the original data in the ratio 3:1 respectively, and set the value for random_state of the training/test split method’s instance as 1
8. A multiple linear regression model is built on the Global Happiness Index dataset ‘GHI_Report.csv’. What is the RMSE of the baseline model?
- 2.00
- 0.50
- 1.06
- 0.75
Answer :- For Answer Click Here
9. A regression model with the following function y=60+5.2x was built to understand the impact of humidity (x) on rainfall (y). The humidity this week is 30 more than the previous week. What is the predicted difference in rainfall?
- 156 mm
- 15.6 mm
- -156 mm
- None of the above
Answer :- For Answer Click Here
10. X and Y are two variables that have a strong linear relationship. Which of the following statements are incorrect?
- There cannot be a negative relationship between the two variables.
- The relationship between the two variables is purely causal.
- One variable may or may not cause a change in the other variable.
- The variables can be positively or negatively correlated with each other
Answer :- For Answer Click Here
| Course Name | Python For Data Science |
| Category | NPTEL Assignment Answer |
| Home | Click Here |
| Join Us on Telegram | Click Here |
About Python For Data Science
The course aims at equipping participants to be able to use python programming for solving data science problems.
CRITERIA TO GET A CERTIFICATE
Average assignment score = 25% of the average of the best 3 assignments out of the total 4 assignments given in the course.
Exam score = 75% of the proctored certification exam score out of 100
Final score = Average assignment score + Exam score
YOU WILL BE ELIGIBLE FOR A CERTIFICATE ONLY IF AVERAGE ASSIGNMENT SCORE >=10/25 AND EXAM SCORE >= 30/75. If one of the 2 criteria is not met, you will not get the certificate even if the Final score >= 40/100.
| Python For Data Science Assignment Answers 2022 | Answer Link |
|---|---|
| Week 1 | Click Here |
| Week 2 | Click Here |
| Week 3 | Click Here |
| Week 4 | Click Here |
NPTEL Python for Data Science Assignment 4 Answers July 2022
1. The power consumption of an individual house in a residential complex has been recorded for the previous year. This data is analysed to predict the power consumption for the next year. Under which type of machine learning problem does this fall under?
a. Classification
b. Regression
c. Reinforcement Learning
d. None of the above
Answer:- b
2. A dataset contains data collected by the Tamil Nadu Pollution Control Board on environmental conditions (154 variables) from one of their monitoring stations. This data is further analyzed to understand the most significant factors that affect the Air Quality Index. The predictive algorithm that can be used in this situation is ___________.
a. Logistic Regression
b. Simple Linear Regression
c. Multiple Linear Regression
d. None of the above
Answer:- c
Answers will be Uploaded Shortly and it will be Notified on Telegram, So JOIN NOW

3. A regression model with the following function y = 60 + 5.2x was built to understand the impact of humidity (x) on rainfall (y). The humidity this week is 30 more than the previous week. What is the predicted difference in rainfall?
a. 156 mm
b. 15.6 mm
c. -156 mm
d. None of the above
Answer:- a
4. Which of the following machine learning techniques would NOT be appropriate to solve the problem given in the problem statement?
a. kNN
b. Random Forest
c. Logistic Regression
d. Linear regression
Answer:- d
5. The plot shown below denotes the percentage distribution of the target column values within the train_data dataframe. Which of the following options are correct?
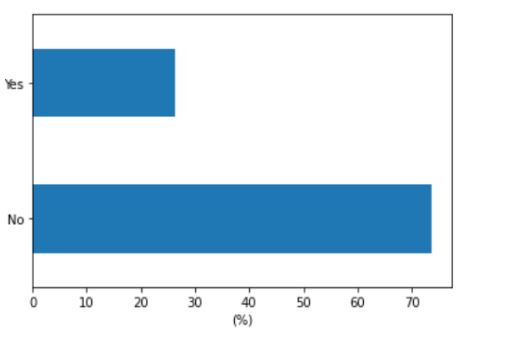
a. Yes > 20, No > 60
b. No > 70, Yes > 20
c. Yes > 30, No > 70
d. Yes > 70, No > 30
Answer:- b
6. After applying logistic regression, what is/are the correct observations from the resultant confusion matrix?
a. True Positive = 29, True Negative = 94
b. True Positive = 94, True Negative = 29
c. False Positive = 5, True Negative = 94
d. None of the above
Answer:- b
👇For Week 04 Assignment Answers👇
7. The logistic regression model built between the input and output variables is checked for its prediction accuracy of the test data. What is the accuracy range (in %) of the predictions made over test data?
a. 60 – 79
b. 90 – 95
c. 30 – 59
d. 80 – 89
Answer:- For Answer Click Here
8. How are categorical variables preprocessed before model building?
a. Standardization
b. Dummy variables
c. Correlation
d. None of the above
Answer:- b
9. A multiple linear regression model is built on the Global Happiness Index dataset “GHI_Report.csv”. What is the RMSE of the baseline model?
a. 2.00
b. 0.50
c. 1.06
d. 0.75
Answer:- c
10. X and Y are two variables that have a strong linear relationship. Which of the following statements are incorrect?
a. There cannot be a negative relationship between the two variables.
b. The relationship between the two variables is purely causal.
c. One variable may or may not cause a change in the other variable.
d. The variables can be positively or negatively correlated with each other.
Answer:- a, c
For More NPTEL Answers:- CLICK HERE
Join Our Telegram:- CLICK HERE
NPTEL Python for Data Science Assignment 4 Answers Jan 2022
Q1. How many unique values are present in the Sbal feature; also, what is the most frequent value within Sbal?
(A) 5, Rs. >= 10,000
(B) 4, Rs. < 1000
(C) 5, Rs. < 1000
(D) 4, ‘1000 <= Rs. < 5,000’
Answer:- (C) 5, Rs. < 1000
The answers will be Uploaded Shortly and it will be notified on Telegram. So Join Now

Q2. Find the average age of those customers who have a credit history [Chist] wherein the dues are not paid earlier.
(A) 35.54
(B) 38.44
(C) 33.00
(D) None of the above
Answer:- (B) 38.44
Q3. A Logistic Regression model is built in which none of the features used are standardized. The train to test proportion is 75:25 and the random state is set to 1. The accuracy of the model is ________.
(A) Less than 50%
(B) Between 50% and 60%
(C) Greater than 70%
(D) None of the above
Answer:- (C) Greater than 70%
Q4. Import StandardScaler() from the sklearn.preprocessing package to standardize the features. Use the same train-test proportion and the random state should be set to 1. After standardizing the logistic regression model, by what percentage has the misclassified samples changed?
(A) 11.11%
(B) 3.7%
(C) 20%
(D) 39.2%
Answer:- (C) 20%
Q5. When KNN classification is applied on the same standardized data at the optimal value for k nearest neighbours, the accuracy achieved is ______.
(A) 64%
(B) 78%
(C) 76.4%
(D) None of the above
Answer:- (A) 64%
Q6. A multiple linear regression model is built on the Global Happiness Index dataset “GHI_Report.csv”. What is the rmse of the baseline model?
(A) 1.99
(B) 0.85
(C) 1.06
(D) 0.33
Answer:- (C) 1.06
Q7. From the multiple linear regression model built on the GHI index, we get an R-squared value of _______ on the test data subset.
(A) 55.63
(B) 45.81
(C) 75.59
(D) 81.46
Answer:- (D) 81.46
Q8. Which of the following statement/s about Linear Regression is / are true?
(A) Linear Regression assumes that there exists a linear relationship between the independent variable and dependent variable.
(B) The error terms are assumed to be independent and normally distributed.
(C) The percentage of variation in the dependent variable as explained by the independent variable/variables is expressed by R-squared value.
(D) Residuals are the product of the predicted value and the actual observed value.
Answer:- (A), (B), (C)
Q9. Which of the following statements is inaccurate about Logistic Regression?
(A) Logistic Regression doesn’t require a linear relationship between the dependent and independent variables.
(B) The value of the logistic function being a probability will range between 0 and 1.
(C) Cost function of Logistic Regression is also called as the Log Loss function.
(D) The dependent variable can be of both numerical or categorical type just like the independent variables.
Answer:- (C) Cost function of Logistic Regression is also called as the Log Loss function.
The answers will be Uploaded Shortly and it will be notified on Telegram. So Join Now
Q10. In a KNN model, by which means do we handle categorical variables?
(A) Standardization
(B) Dummy variables
(C) Correlation
(D) None of the above
Answer:- (B) Dummy variables
Disclaimer:- We do not claim 100% surety of solutions, these solutions are based on our sole expertise, and by using posting these answers we are simply looking to help students as a reference, so we urge do your assignment on your own.
For More NPTEL Answers:- CLICK HERE
Join Our Telegram:- CLICK HERE
NPTEL Python for Data Science Assignment 4 Answers 2022:- All the Answers provided below to help the students as a reference, You must submit your assignment at your own knowledge.