Big Data Computing Assignment 6 Answers 2021:- We do not claim 100% surety of answers, these answers are based on our sole knowledge, and by posting these answers we are just trying to help students, so we urge do your assignment on your own.
NPTEL ALL WEEK ASSIGNMENT ANSWERS:-
- Soft Skill Assignment Answers
- Project Management For Managers Answer
- Semiconducter Devices And Circuit Answer
- Problem Solving Through Programming In C Answer
Q1. Which of the following is required by K-means clustering ?
(A) Defined distance metric
(B) Number of clusters
(C) Initial guess as to cluster centroids
(D) All of the mentioned
Ans:- (D) All of the mentioned
Q2. Identify the correct statement in context of Regressive model of Machine Learning.
(A) Regressive model predicts a numeric value instead of category.
(B) Regressive model organizes similar item in your dataset into groups.
(C) Regressive model comes up with a set of rules to capture associations between items or events.
(D) None of the Mentioned
Ans:- (A) Regressive model predicts a numeric value instead of category.
Q3. Which of the following tasks can be best solved using Clustering ?
(A) Predicting the amount of rainfall based on various cues
(B) Training a robot to solve a maze
(C) Detecting fraudulent credit card transactions
(D) All of the mentioned
Ans:- (C) Detecting fraudulent credit card transactions
Q4. Identify the correct method for choosing the value of ‘k’ in k-means algorithm ?
(A) Dimensionality reduction
(B) Elbow method
(C) Both Dimensionality reduction and Elbow method
(D) Data partitioning
Ans:- (C) Both Dimensionality reduction and Elbow method
Q5. Identify the correct statement(s) in context of overfitting in decision trees:
Statement I: The idea of Pre-pruning is to stop tree induction before a fully grown tree is built, that perfectly fits the training data.
Statement II: The idea of Post-pruning is to grow a tree to its maximum size and then remove the nodes using a top-bottom approach.
(A) Only Statement I is true
(B) Only Statement II is true
(C) Both Statements are true
(D) Both Statements are false
Ans:- (A) Only Statement I is true
Q6. Which of the following options is/are true for K-fold cross-validation ?
1. Increase in K will result in higher time required to cross validate the result.
2. Higher values of K will result in higher confidence on the cross-validation result as compared to lower value of K.
3. If K=N, then it is called Leave one out cross validation, where N is the number of observations.
(A) 1 and 2
(B) 2 and 3
(C) 1 and 3
(D) 1, 2 and 3
Ans:- (D) 1, 2 and 3
Q7. Imagine you are working on a project which is a binary classification problem. You trained a model on training dataset and get the below confusion matrix on validation dataset.
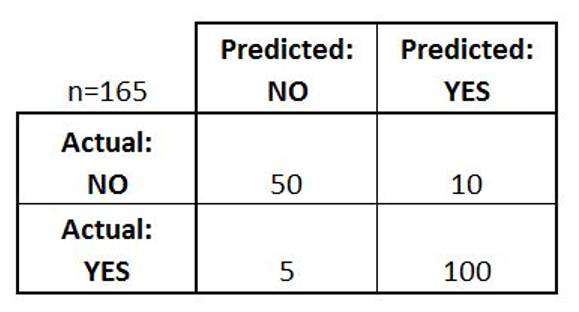
Based on the above confusion matrix, choose which option(s) below will give you correct predictions ?
1. Accuracy is ~0.91
2. Misclassification rate is ~ 0.91
3. False positive rate is ~0.95
4. True positive rate is ~0.95
(A) 1 and 3
(B) 2 and 4
(C) 2 and 3
(D) 1 and 4
Ans:- (D) 1 and 4
Q8. Identify the correct statement(s) in context of machine learning approaches:
Statement I: In supervised approaches, the target that the model is predicting is unknown or unavailable. This means that you have unlabeled data.
Statement II: In unsupervised approaches the target, which is what the model is predicting, is provided. This is referred to as having labeled data because the target is labeled for every sample that you have in your data set.
(A Only Statement I is true
(B) Only Statement II is true
(C) Both Statements are false
(D) Both Statements are true
Ans:- (C) Both Statements are false
Big Data Computing Assignment 6 Answers 2021:- We do not claim 100% surety of answers, these answers are based on our sole knowledge, and by posting these answers we are just trying to help students, so we urge do your assignment on your own.