NPTEL Introduction to Machine Learning Assignment 3 Answers 2023:- In This article, we have provided the answers of Introduction to Machine Learning Assignment 3 You must submit your assignment to your own knowledge.
ALSO READ :-
NPTEL Registration Steps [July – Dec 2022]
NPTEL Exam Pattern Tips & Top Tricks [2022]
NPTEL Exam Result 2022 | NPTEL Swayam Result DownloadNPTEL Introduction To Machine Learning Week 3 Assignment Answer 2023
1. Which of the following are differences between LDA and Logistic Regression?
- Logistic Regression is typically suited for binary classification, whereas LDA is directly applicable to multi-class problems
- Logistic Regression is robust to outliers whereas LDA is sensitive to outliers
- both (a) and (b)
- None of these
Answer :- c
2. We have two classes in our dataset. The two classes have the same mean but different variance.
LDA can classify them perfectly.
LDA can NOT classify them perfectly.
LDA is not applicable in data with these properties
Insufficient information
Answer :- b
3. We have two classes in our dataset. The two classes have the same variance but different mean.
LDA can classify them perfectly.
LDA can NOT classify them perfectly.
LDA is not applicable in data with these properties
Insufficient information
Answer :- d
4. Given the following distribution of data points:
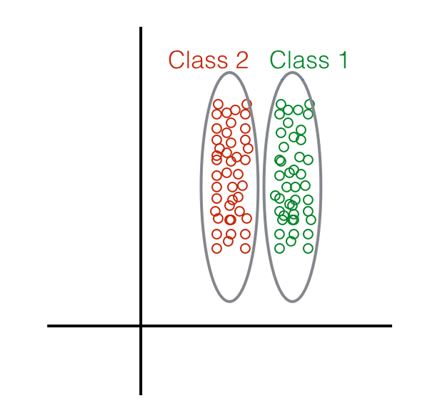
What method would you choose to perform Dimensionality Reduction?
Linear Discriminant Analysis
Principal Component Analysis
Both LDA and/or PCA.
None of the above.
Answer :- a
5. If log(1−p(x)/1+p(x))=β0+βx What is p(x) ?
p(x)=1+eβ0+βx / eβ0+βx
p(x)=1+eβ0+βx / 1−eβ0+βx
p(x)=eβ0+βx / 1+eβ0+βx
p(x)=1−eβ0+βx / 1+eβ0+βx
Answer :- d
6. For the two classes ’+’ and ’-’ shown below.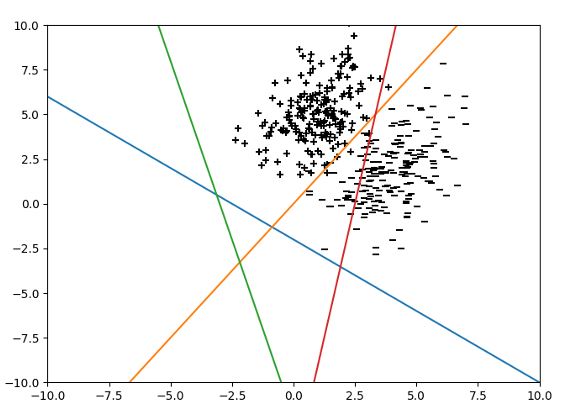
While performing LDA on it, which line is the most appropriate for projecting data points?
Red
Orange
Blue
Green
Answer :- c
7. Which of these techniques do we use to optimise Logistic Regression:
Least Square Error
Maximum Likelihood
(a) or (b) are equally good
(a) and (b) perform very poorly, so we generally avoid using Logistic Regression
None of these
Answer :- b
8. LDA assumes that the class data is distributed as:
Poisson
Uniform
Gaussian
LDA makes no such assumption.
Answer :- c
9. Suppose we have two variables, X and Y (the dependent variable), and we wish to find their relation. An expert tells us that relation between the two has the form Y=meX+c. Suppose the samples of the variables X and Y are available to us. Is it possible to apply linear regression to this data to estimate the values of m and c ?
No.
Yes.
Insufficient information.
None of the above.
Answer :- b
10. What might happen to our logistic regression model if the number of features is more than the number of samples in our dataset?
It will remain unaffected
It will not find a hyperplane as the decision boundary
It will over fit
None of the above
Answer :- c
NPTEL Introduction to Machine Learning Assignment 3 Answers [July 2022]
1. For linear classification we use:
a. A linear function to separate the classes.
b. A linear function to model the data.
c. A linear loss.
d. Non-linear function to fit the data.
Answer:- a
2. Logit transformation for Pr(X=1) for given data is S=[0,1,1,0,1,0,1]
a. 3/4
b. 4/3
c. 4/7
d. 3/7
Answer:- b
Answers will be Uploaded Shortly and it will be Notified on Telegram, So JOIN NOW

3. The output of binary class logistic regression lies in this range.
a. [−∞,∞]
b. [−1,1]
c. [0,1]
d. [−∞,0]
Answer:- c
4. If log(1−p(x)1+p(x))=β0+βxlog What is p(x)p(x)?
Answer:- d
5. Logistic regression is robust to outliers. Why?
a. The squashing of output values between [0, 1] dampens the affect of outliers.
b. Linear models are robust to outliers.
c. The parameters in logistic regression tend to take small values due to the nature of the problem setting and hence outliers get translated to the same range as other samples.
d. The given statement is false.
Answer:- a
6. Aim of LDA is (multiple options may apply)
a. Minimize intra-class variability.
b. Maximize intra-class variability.
c. Minimize the distance between the mean of classes
d. Maximize the distance between the mean of classes
Answer:- a, d
👇For Week 04 Assignment Answers👇
7. We have two classes in our dataset with mean 0 and 1, and variance 2 and 3.
a. LDA may be able to classify them perfectly.
b. LDA will definitely be able to classify them perfectly.
c. LDA will definitely NOT be able to classify them perfectly.
d. None of the above.
Answer:- c
8. We have two classes in our dataset with mean 0 and 5, and variance 1 and 2.
a. LDA may be able to classify them perfectly.
b. LDA will definitely be able to classify them perfectly.
c. LDA will definitely NOT be able to classify them perfectly.
d. None of the above.
Answer:- a
9. For the two classes ’+’ and ’-’ shown below.
While performing LDA on it, which line is the most appropriate for projecting data points?
a. Red
b. Orange
c. Blue
d. Green
Answer:- c
10. LDA assumes that the class data is distributed as:
a. Poisson
b. Uniform
c. Gaussian
d. LDA makes no such assumption.
Answer:- c
For More NPTEL Answers:- CLICK HERE
Join Our Telegram:- CLICK HERE
| Introduction to Machine Learning | Answers |
| Assignment 1 | Click Here |
| Assignment 2 | Click Here |
| Assignment 3 | Click Here |
| Assignment 4 | Click Here |
| Assignment 5 | Click Here |
| Assignment 6 | Click Here |
| Assignment 7 | Click Here |
| Assignment 8 | Click Here |
| Assignment 9 | Click Here |
| Assignment 10 | Click Here |
| Assignment 11 | NA |
| Assignment 12 | NA |
What is Introduction to Machine Learning?
With the increased availability of data from varied sources there has been increasing attention paid to the various data driven disciplines such as analytics and machine learning. In this course we intend to introduce some of the basic concepts of machine learning from a mathematically well motivated perspective. We will cover the different learning paradigms and some of the more popular algorithms and architectures used in each of these paradigms.
CRITERIA TO GET A CERTIFICATE
Average assignment score = 25% of the average of best 8 assignments out of the total 12 assignments given in the course.
Exam score = 75% of the proctored certification exam score out of 100
Final score = Average assignment score + Exam score
YOU WILL BE ELIGIBLE FOR A CERTIFICATE ONLY IF THE AVERAGE ASSIGNMENT SCORE >=10/25 AND EXAM SCORE >= 30/75. If one of the 2 criteria is not met, you will not get the certificate even if the Final score >= 40/100.
| Introduction to Machine Learning | Answers |
| Assignment 1 | Click Here |
| Assignment 2 | Click Here |
| Assignment 3 | Click Here |
| Assignment 4 | Click Here |
| Assignment 5 | Click Here |
| Assignment 6 | NA |
| Assignment 7 | NA |
| Assignment 8 | NA |
| Assignment 9 | NA |
| Assignment 10 | NA |
| Assignment 11 | NA |
| Assignment 12 | NA |
NPTEL Introduction to Machine Learning Assignment 3 Answers [Jan 2022]
Q1. consider the case where two classes follow Gaussian distribution which are centered at (6, 8) and (−6, −4) and have identity
covariance matrix. Which of the following is the separating decision boundary using LDA assuming the priors to be equal?
(A) x+y=2
(B) y−x=2
(C) x=y
(D) both (a) and (b)
(E) None of the above
(F) Can not be found from the given information
Answer:- (A) x+y=2
👇FOR NEXT WEEK ASSIGNMENT ANSWERS👇

Q2. Which of the following are differences between PCR and LDA?
(A) PCR is unsupervised whereas LDA is supervised
(B) PCR maximizes the variance in the data whereas LDA maximizes the separation between the classes
(C) both (a) and (b)
(D) None of these
Answer:- (A) PCR is unsupervised whereas LDA is supervised
Q3. Which of the following are differences between LDA and Logistic Regression?
(A) Logistic Regression is typically suited for binary classification, whereas LDA is directly applicable to multi-class problems
(B) Logistic Regression is robust to outliers whereas LDA is sensitive to outliers
(C) both (a) and (b)
(D) None of these
Answer:- (C) both (a) and (b)
ALSO READ :-
NPTEL Registration Steps [July – Dec 2022]
NPTEL Exam Pattern Tips & Top Tricks [2022]
NPTEL Exam Result 2022 | NPTEL Swayam Result Download
Q4. We have two classes in our dataset. The two classes have the same mean but different variance.
- LDA can classify them perfectly.
- LDA can NOT classify them perfectly.
- LDA is not applicable in data with these properties
- Insufficient information
Answer:- 2. LDA can NOT classify them perfectly.
Q5. We have two classes in our dataset. The two classes have the same variance but different mean.
- LDA can classify them perfectly.
- LDA can NOT classify them perfectly.
- LDA is not applicable in data with these properties
- Insufficient information
Answer:- 1. LDA can classify them perfectly.
👇FOR NEXT WEEK ASSIGNMENT ANSWERS👇
Q6. Which of these techniques do we use to optimise Logistic Regression:
- Least Square Error
- Maximum Likelihood
- (a) or (b) are equally good
- (a) and (b) perform very poorly, so we generally avoid using Logistic Regression
- None of these
Answer:- 2.Maximum Likelihood
Q7. Suppose we have two variables, X and Y (the dependent variable), and we wish to find their relation. An expert tells us that relation
between the two has the form Y=meX+c. Suppose the samples of the variables X and Y are available to us. Is it possible to apply
linear regression to this data to estimate the values of m and c?
- no
- yes
- insufficient information
Answer:- 2.yes
Q8. What might happen to our logistic regression model if the number of features is more than the number of samples in our dataset?
- It will remain unaffected
- It will not find a hyperplane as the decision boundary
- It will overfit
- None of the above
👇FOR NEXT WEEK ASSIGNMENT ANSWERS👇
Answer:- 3. It will overfit
Q9. Logistic regression also has an application in
- Regression problems
- Sensitivity analysis
- Both (a) and (b)
- None of the above
Answer:- 3. Both (a) and (b)
Q10. Consider the following datasets:
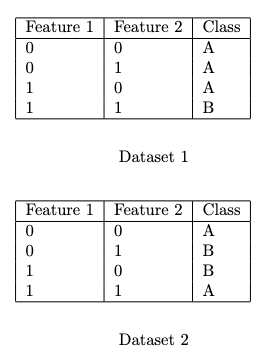
Which of these datasets can you achieve zero training error using Logistic Regression (without any additional feature transformations)?
- Both the datasets
- Only on dataset 1
- Only on dataset 2
- None of the datasets
Answer:- For Answer Click Here
👇FOR NEXT WEEK ASSIGNMENT ANSWERS👇
NPTEL Introduction to Machine Learning Assignment 3 Answers 2022:- In This article, we have provided the answers of Introduction to Machine Learning Assignment 3
Disclaimer:- We do not claim 100% surety of solutions, these solutions are based on our sole expertise, and by using posting these answers we are simply looking to help students as a reference, so we urge do your assignment on your own.
For More NPTEL Answers:- CLICK HERE
Join Our Telegram:- CLICK HERE
4 thoughts on “NPTEL Introduction to Machine Learning Assignment 3 Answers 2023”