Introduction To Machine Learning – IITKGP Assignment 5 Answers NPTEL 2022 [July-Dec] :- In this post, We have provided answers of NPTEL Introduction to Machine Learning – IITKGP Assignment 5 Week 5. We provided answers here only for reference. Plz, do your assignment at your own knowledge.
About Introduction To Machine Learning – IITKGP
This course provides a concise introduction to the fundamental concepts in machine learning and popular machine learning algorithms. We will cover the standard and most popular supervised learning algorithms including linear regression, logistic regression, decision trees, k-nearest neighbour, an introduction to Bayesian learning and the naïve Bayes algorithm, support vector machines and kernels and neural networks with an introduction to Deep Learning. We will also cover the basic clustering algorithms. Feature reduction methods will also be discussed. We will introduce the basics of computational learning theory. In the course we will discuss various issues related to the application of machine learning algorithms. We will discuss hypothesis space, overfitting, bias and variance, tradeoffs between representational power and learnability, evaluation strategies and cross-validation. The course will be accompanied by hands-on problem solving with programming in Python and some tutorial sessions.
CRITERIA TO GET A CERTIFICATE
Average assignment score = 25% of average of best 6 assignments out of the total 8 assignments given in the course.
Exam score = 75% of the proctored certification exam score out of 100
Final score = Average assignment score + Exam score
YOU WILL BE ELIGIBLE FOR A CERTIFICATE ONLY IF AVERAGE ASSIGNMENT SCORE >=10/25 AND EXAM SCORE >= 30/75. If one of the 2 criteria is not met, you will not get the certificate even if the Final score >= 40/100.
Introduction To Machine Learning – IITKGP Assignment 5 Answers NPTEL 2022 [July-Dec]
1. What would be the ideal complexıty of the curve which can be used for separatıng the two classes shown in the image below?
A) Linear
B) Quadratic
c) Cubic
D) nsutticient data to draw conclusion
Answer:- a
2. Which oft the following optiOn is ruef
A) Linear regression eror values have to normally distributed but not in the caseof the logistic regression
B) Logistic regression values have to be normally distributed but not in the case of the linear regression
C) Both linear and logistic regression error values have to be normally distributed
D) Both linear and logistic regression eror values need not to be normally distributed
Answer:- a
Answers will be Uploaded Shortly and it will be Notified on Telegram, So JOIN NOW

3. Which of the following methods do we use to best fit the data in Logistic Regression?
A) Manhattan distance
B) Maximum Likelihood
c) Jaccard distance
D) Both A and B
Answer:- b
4.
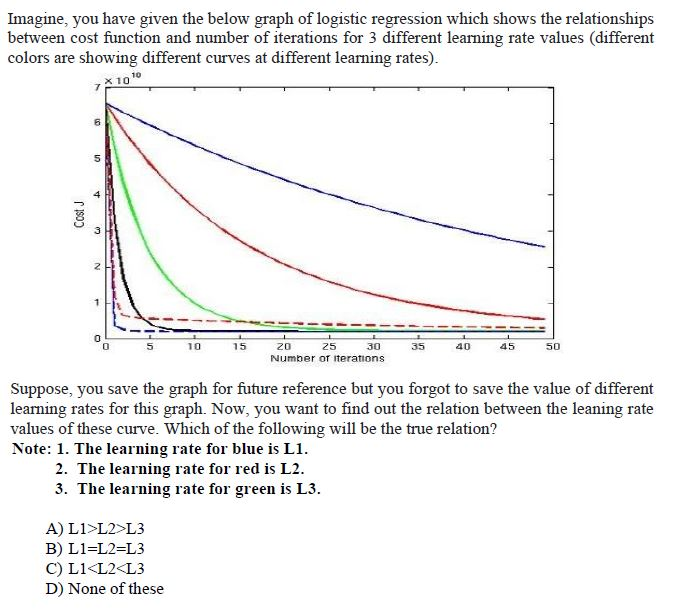
Answer:- c
5. State whether True or False. After training an SVM, we can discard all examples which are not support vectors and can still classify new examples.
A) TRUE
B) FALSE
Answer:- a
6. Suppose you are dealing with 3 class classification problem and you want to tran a SVM model on the data for that you are using One-vS-all method. How many times we need to train our SVM model in such case?
A) 1
B) 2
C) 3
D) 4
Answer:- c
👇For Week 06 Assignment Answers👇
7. What is/are true about kenel in SVM? 1. Kemel function map low dimensional data to high dimensional space 2. It’s a similarıty function
A) 1
B) 2
C)1 and 2
D) None of these.
Answer:- c
8. Suppose you are usıng RBFkermel in SVM with high Gamma value. What does this signufy?
A) The model would consider even far away points from hyperplane for modelling.
B) The model would consider only the points close to the hyperplane for modellıng8
C)The model would not be aftected by distance of points from hyperplane for modelling.
D) None of the above
Answer:- b
9. Below are the labelled instances of 2 classes and hand drawn decision boundaries for logistic regression. Which of the following figure demonstrates overfitting of the training data?
A) A
B) B
C) C
D) None of these
Answer:- c
10. What do you conclude after seeing the visualization in previous question? C1. The training error in first plot is higher as compared to the second and third plot. C2. The best model for this regression problem is the last (third) plot because it has minimum training error (zero). C3. Out of the 3 models, the second model is expected to perform best on unseen data. C4. All will perform similarly because we have not seen the test data.
A) C1 and c2
B) C1 and c3
C) C2 and c3
D) C4
Answer:- b
For More NPTEL Answers:- CLICK HERE
Join Our Telegram:- CLICK HERE